Today during one of the lectures at IIMB, I was introduced to a book called '
The Box' by Mark Levinson.
The book narrates the story of how the invention of the shipping container completely changed the face of global commerce. A snippet from the book -
"the cost of transporting goods was decisive in determining what products they would make, where they would manufacture and sell them, and whether importing or exporting was worthwhile. Shipping containers didn't just cut costs but rather changed the whole economic landscape. It changed the global consumption patterns, revitalizing industries in decay, and even allowing new industries to take shape."
A nice video explaining the same is available on YouTube -
https://www.youtube.com/watch?v=IDmLEFDDd-c
A similar revolution is happening in the IT landscape by means of a new software container concept called as
Docker. In fact, the logo of Docker contains an image of shipping containers :)
Docker provides an additional layer of abstraction (through a docker engine, a.k.a docker server) that can run a docker container containing any payload. This has made it really easy to package and deploy applications from one environment to the other.
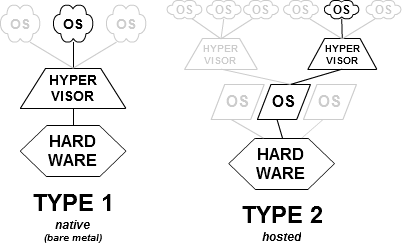
A Docker container encapsulates all the code and its dependencies required to run an application. They are quite different from virtualization technology. A hypervisor running on a 'Host OS' essentially loads the entire 'Guest OS' and then runs the apps on top of it. In Docker architecture, you have a Docker engine (a.k.a Docker server) running on the Host OS. Each Docker server can host many docker containers. Docker clients can remotely talk with Docker servers using a REST API to start/stop containers, patch them with new versions of app, etc.
A good article describing the differences between them is available here -
http://scm.zoomquiet.io/data/20131004215734/index.html
 |
| Source: http://scm.zoomquiet.io/data/20131004215734/index.html |
All docker containers are isolated from each other using the Linux Kernel process isolation features.
In fact, it is these OS-level virtualization features of Linux that has enabled Docker to become so successful.
Other OS such as Windows or MacOS do not have such features as part of their core kernel to support Docker. Hence the current way to run Docker on them is to create a light-weight Linux VM (
boot2docker) and run docker within it. A good article explaining how to run Docker on MacOS is here -
http://viget.com/extend/how-to-use-docker-on-os-x-the-missing-guide
Docker was so successful that even Microsoft was forced to admit that it was a force to reckon with !
Microsoft is now working with Docker to enable native support for docker containers in its new Nano server operating system -
http://thenewstack.io/docker-just-changed-windows-server-as-we-know-it/
This IMHO, is going to be a big game-changer for MS and would catapult the server OS as a strong contender for Cloud infrastructure.